Image annotation pipeline

Picture by Sigmund
Building an image cleansing and annotation pipeline for Farmy.ai startup.
what is a data pipeline?
A data pipeline is a series of steps to organize the data life cycle including data ingestion, data processing, and data storage, starting from one or more data sources and end-up in one or more data sinks.
What is data annotation?
Data annotation is the process of adding labels and semantics to data so we can use it to train machine learning models. It may vary depending on the type of data. For instance, it could be image annotation, text annotation, audio annotation, video annotation, etc.
The main power of a high-quality data annotation is accurate human intervention, choosing highly skilled experts in the target domain is critical.
Image annotation data pipeline
The data pipeline ingests images with associated metadata into the Data Lake and then loads them for cleansing, before they become ready for annotation.
Our data annotation pipeline mainly manages various stages of the annotation process. It helps us reduce the overhead of manual tasks, such as moving images between phases, assigning tasks to annotators, checking completed phases, and finding conflicts in image annotations when exporting them.
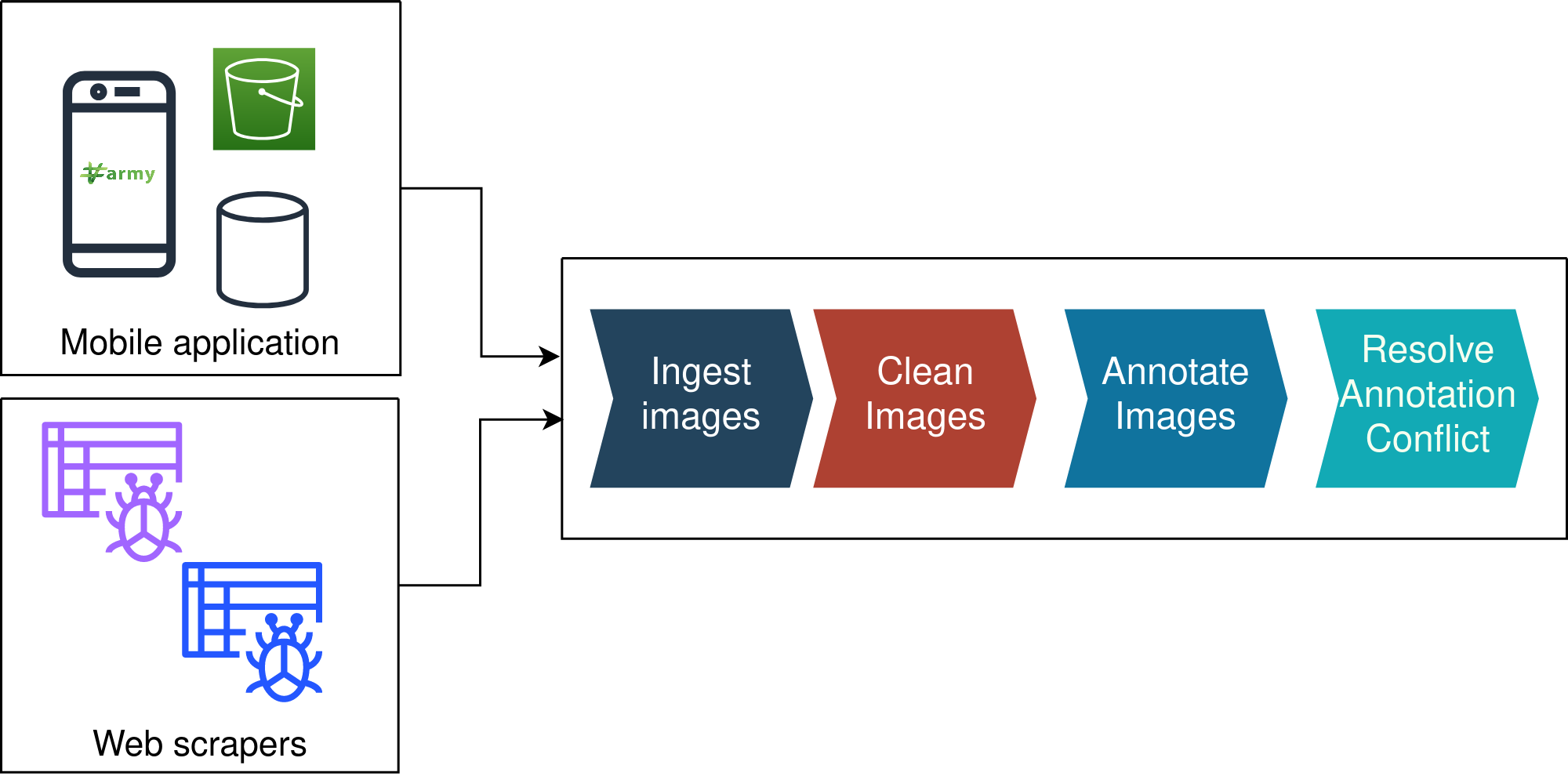
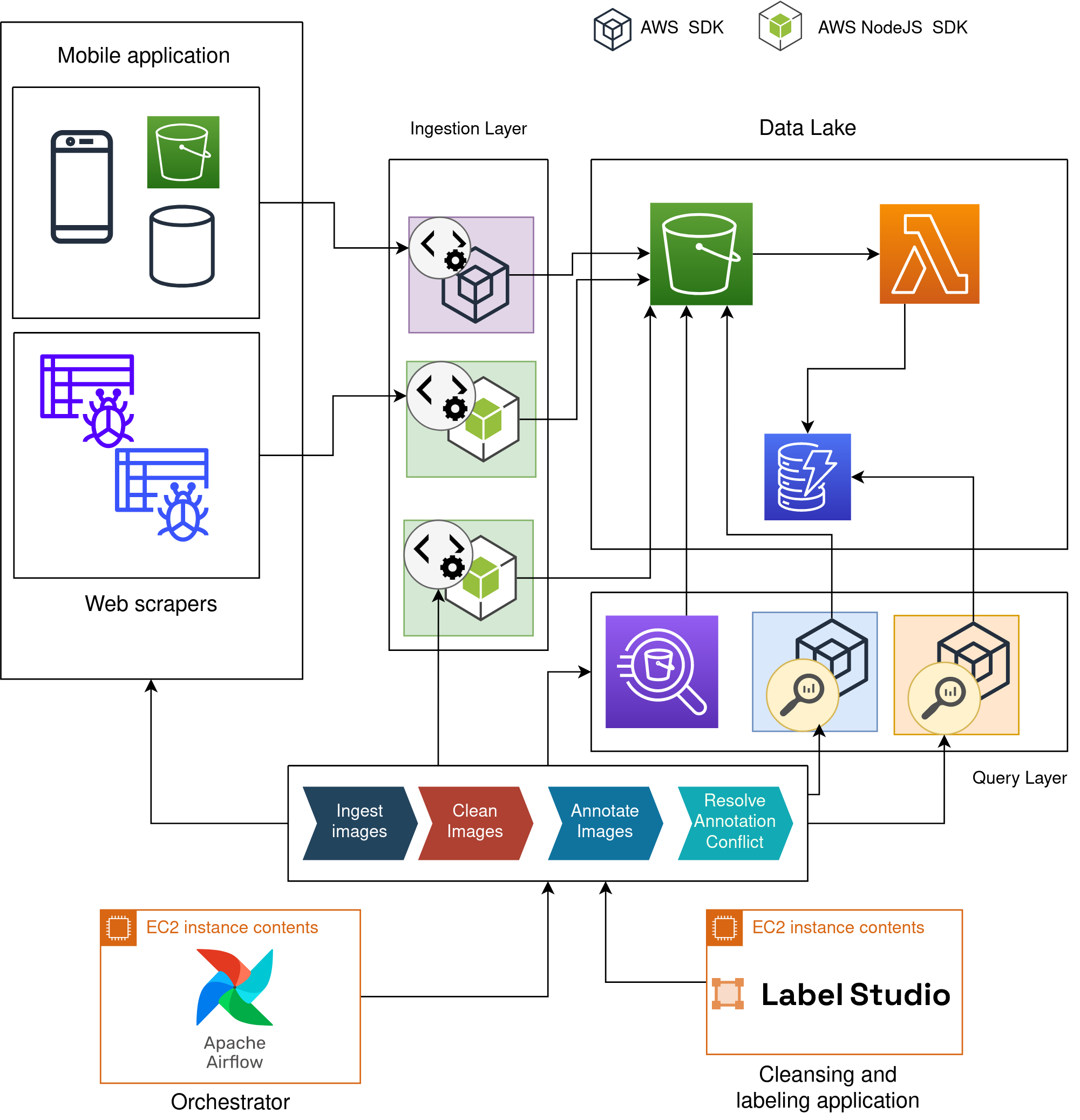
The building block of the data pipeline is the Data Lake. The pipeline is well integrated with the data lake, but it is unaware of the Data-Lake architecture and infrastructure.
We perform data cleansing and annotation in an independent application, the data pipeline connects between the data lake and the annotation application by acting as a producer or consumer of the data lake through two layers one is the ingestion layer and the second is the query layer.

Deploying the pipeline to AWS
The full architecture of the Farmy Data Lake and data pipeline is deployed on the AWS infrastructure. The ingesting layer ingests data from the mobile application, and web scrapers and stores it in AWS S3. A Lambda function listens for events triggered by AWS S3 to update the data catalog, which uses AWS DynamoDB to store the metadata.
The query layer provides preconfigured libraries and AWS Athena for searching AWS DynamoDB and AWS S3. The data pipeline is orchestrated by Apache Airflow deployed on an AWS EC2 instance. the pipeline uses Data Lake and Label Studio that is containerized in Docker and deployed on an EC2 instance.
Orchestrating the pipeline
Managing and provisioning the data pipeline workflow is particularly challenging because orchestration involves coordinating the various tasks. The keystone of orchestrating is automation. Orchestrating of a data pipeline includes scheduling of tasks, resource, execution environment, retries, error handling, logs, etc.
There are many open-source tools that can reduce the overhead of orchestration, and let us focus more on logic. clearly we still need to model the data pipeline and represent it as a workflow.
Tools used
AWS was the primary infrastructure we use many AWS services like S3, Lambda, DynamoDB, EC2, and Athena. We also use many open source projects and languages, like Python, NodeJs, Apache Airflow, Label Studio, and Docker.
Conclusion
We have shown how we build the data pipeline using the data lake architecture, We have shown how well-structured data lake architecture can help us build data pipelines efficiently. we also illustrated the critical role of orchestration to execute and monitor the data pipeline.
